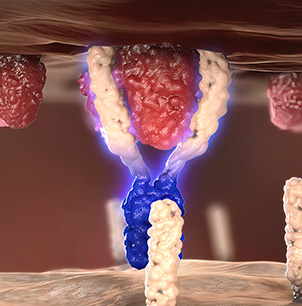
借助“蛋白冠”及Vorman效应,使更强结合亲和力的蛋白与早期吸附的蛋白发生竞争性置换,针对生物样本中的低丰度蛋白进行高效富集。
MagicOmics DMB试剂盒不仅可以广泛应用于血浆血清、脑脊液、尿液、细胞上清液等样本类型而且适用于人、鼠、兔、羊、牛等不同物种。

在人群队列中进行基因组和蛋白组分析,通过全基因组关联分析筛选疾病遗传关联蛋白,进一步研究候选位点功能机制及调控网络,探索疾病的作用机制和潜在治疗靶点

通过发现队列及验证队列筛选出与疾病相关的蛋 白质,可应用于疾病的诊断、分期和预后治疗

分析患者在发病过程或患者与对照间血浆蛋白质 的变化,寻找差异表达蛋白并进行功能分析,进一步揭示疾病的发病机制
全流程全自动化样本前处理结合最新高分辨质谱仪timsTOF HT进行蛋白质组学检测,助力生物标志物的开拓
普通深度、高深度最低仅需50uL血浆样本;
最快10个工作日交付结果。
技术成果发表在《Analytica Chimica Acta》、《质谱学报》。两篇文章对市面上多种低丰度蛋白富集的方法进行了测试,结果表明DMB试剂盒能够富集更多的血浆、血清低丰度蛋白,助力血液蛋白标志物的发现。
血浆蛋白质组生物信息分析:标准分析+血浆特色分析+高级分析
高级分析:
标志物筛选:机器学习算法筛选蛋白标志物
PWAS:全蛋白质组关联分析
多组学联合分析:蛋白质组代谢组联合分析;蛋白质组转录组联合分析




利用自主研发的血浆低丰度蛋白富集磁珠试剂盒(MagicOmics-DMB)对血浆样本中的低丰度蛋白进行富集,使用自主研发的全流程自动化前处理机器人(MagicOmics-AP-96)进行样本制备,然后使用高通量timsTOF HT质谱仪进行蛋白质检测,实现血浆蛋白质组超高深度覆盖。与富集前的血浆样本相比,利用MagicOmics-DMB富集样本的蛋白质鉴定数目大大提升,从富集前的409个蛋白质,提升至富集后的6071个。




发表期刊:Analytica Chimica Acta
影响因子:5.7
发表单位:中国人民解放军总医院&青莲百奥
发表时间:2023.07.04

发表期刊:质谱学报
影响因子:/
发表单位:中国计量大学
发表时间:2024.03.19
| 样本类型 | LFQ/ DIA/PRM | TMT | 内源性多肽 | HILIC糖基化 |
| 血浆/血清/(不去除高丰度) | 5μL | 10 μL | 200μL | 10μL |
| 血浆/血清/(去除高丰度-伯乐) | 100 μL | 300μL | 500μL | / |
| 血浆/血清(去除高丰度-TOP2/TOP14) | 50μL | 50μL | 500μL | / |
| 血浆/血清(去除高丰度-DMB蛋白冠) | 50μL | / | / | 500 μL |

基于“蛋白冠”及“Vorman效应”,通过对纳米磁珠表面进行特殊的修饰,使其对血浆样品的中、低丰度蛋白质具有更高的亲和力,以达到非特异性去除血浆高丰度蛋白质的目的
血清:
1)使用真空采血管收集血液(不含抗凝剂,红盖);
2)轻轻地上下颠倒混匀 5-6 次;
3)4℃,静置 15-30 min,1100 g 离心 10 min;
4)用移液器将上层淡黄色血清转移到离心管中,瞬时离心。
5)液氮速冻,- 80℃短期保存,干冰寄送。
注:1)样品制备过程中不能溶血。2)血清参考得率:30%~50%(例如:1mL全血大约能得0.3~0.5mL血清)。
血浆:
1)使用 EDTA 抗凝剂(空采血管帽盖为紫色)的血常规管采集血液(不能使用含有肝素抗凝剂的采血管);
2)轻轻地上下颠倒混匀 8-10 次; 立即 4℃,1200 g 离心 10min;
3)用移液器将血浆转移到离心管中,瞬时离心。
4)液氮速冻,- 80℃短期保存,干冰寄送。
注:1)如果血浆样本需要去除高丰度蛋白,在收集样本时不能使用肝素抗凝剂,只能使用EDTA等其他抗凝剂。2)血浆参考得率:约50%(例如:1mL 全血大约能得 0.5mL 血浆)。
如果问题不明确,队列越大越好。如果有特定的临床目的,可以使用几十例的样本加上验证队列。一般在50例及以上,机器学习构建模型的准确性更高。